Lo specifico interesse in questo caso è capire se differenti modelli di volatilità si comportano meglio in condizioni di improvviso stress dei mercati. Per essere più precisi, confronteremo la consueta procedura econometrica, fatta di diagnosi, selezione modello, stima e controllo del modello ex post, con una stima del VaR molto in voga tra i practioners, cioè quella basata su una finestra di osservazioni rolling (nel nostro esempio 200, 100, e 50 giorni). Cercheremo di capire se previsioni di VaR basate su differenti modelli di volatilità siano più robuste di altre: il tutto con particolare riferimento al periodo Settembre – Ottobre 2008. I dati che utilizzeremo sono i rendimenti giornalieri close-to-close dell’indice S&P 500 scaricato da Yahoo Finance. Cosa a mio modesto avviso ancora più interessante, cercheremo di capire se misure di volatilità meno sofisticate (tipo una stima rolling window della volatilità), quotidianamente usate anche su blasonati desk di banche d’investimento, si comportano meglio o peggio di modelli più avanzati, come qualche membro di rilievo della popolosa famiglia GARCH.
Un po’ di indicazioni sulle specifiche del back test eseguito. Non è stato utilizzato un vero e proprio modello per la media, d’altronde ben pochi practioners lo fanno. Tuttavia, ho stimato un termine costante solo con l’intento di rendere la serie a media nulla e dunque ricreare le condizioni per la stima GARCH tradizionale (che, come ormai anche i muri sanno, si applica a serie white noise). Per coerenza (per par condicio avrebbe detto qualche ex Capo dello Stato) la medesima operazione è stata condotta anche sulle stime rolling. Pertanto alla fine il VaR è stato calcolato come il percentile al 95% della distribuzione attesa dei rendimenti: inutile dire che essa è pesantemente influenzata dalla volatilità. L’idea di fondo è però un’altra: siamo sicuri che la volatilità da sola sia sufficiente a distribuire massa di probabilità nelle code, così da generare un VaR robusto, anche in presenza di eventi estremi? Capovolgendo i termini della questione, sarebbe peraltro anche lecito domandarsi: siamo certi che l’utilizzo di modelli dinamici di volatilità dia un vantaggio “sistematico” rispetto ad approcci più euristici, come quello delle stime rolling window? Proprio perché non siamo certi di niente (a parte che quest’anno la Juve non vince nemmeno la tombola di Viggiù, ahimè) , intendiamo condurre questa analisi. Come diceva un mio grandissimo prof di quando facevo il dottorato, “per rispondere con cognizione di causa bisogna prima studiare e verificare. Per rispondere e basta è sufficiente aprire bocca e dare aria”.
Prima di passare all'esame dei grafici riferiti alle previsioni dei singoli modelli riporto nel diagramma seguente l'andamento delle volatilità misurate secondo ciascun approccio (asse sinistro) a fronte dell'andamento, ullo stesso periodo, dell'indice S&P 500 (asse destro).

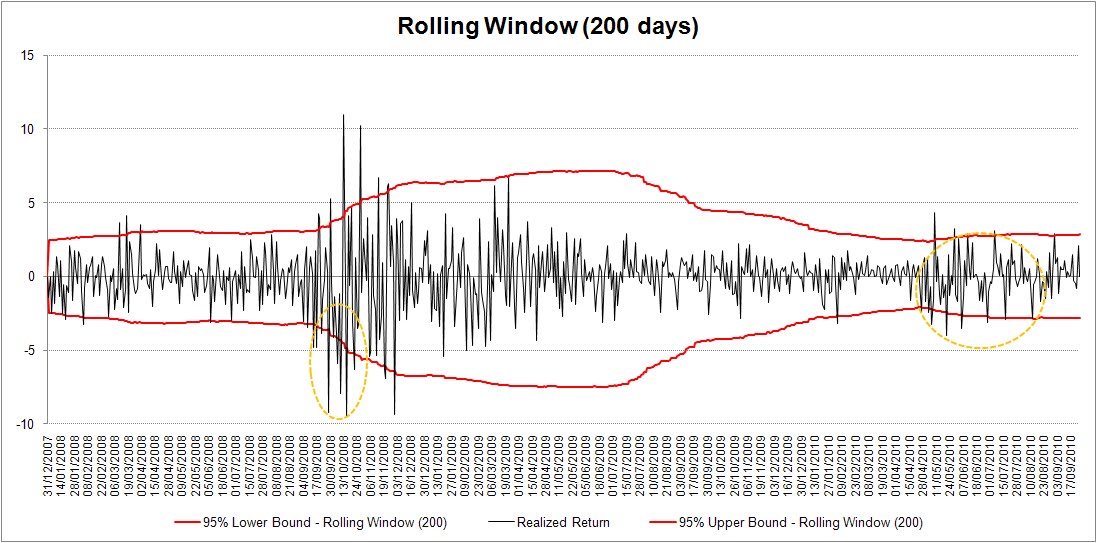
Come si vede, le stime rolling di volatilità sono poco reattive alle fasi di stress del mercato. In altri termini, sono lente nell'incorporare l'arrivo di nuova informazione, in particolare quella di segno negativo. E' dunque lecito aspettarsi che la costruzione di un VaR basata su queste non sia efficiente, ma più avanti avremo modo di valutare nello specifico i risultati. I vari modelli GARCH utilizzati invece esibiscono la tipica clusterizzazione, ossia la concentrazione in picchi della volatilità. Come è noto, si tratta di una caratteristica peculiare dei mercati finanziari: a fasi di alta volatilità solitamente seguono periodi di volatilità altrettanto elevata. Ovviamente nessun modello, per quanto sofisticato, è in grado di anticipare il primo significativo shock che colpisce la serie considerata: ma, rispetto ad approcci più semplicistici, è in grado di allinearsi più rapidamente al nuovo "regime" di volatilità che si è ventuo instaurando.
Di seguito trovate i grafici del VaR out-of-sample prodotto da ciascuno dei modelli. Ma pare giusto a questo punto descrivere in maneria molto sintetica almeno i modelli GARCH utilizzati, rimandando alle pubblicazioni specialistiche per i dettagli, ovviamente. Indico con y(t+1) e sigma2(t+1) rispettivamene il rendimento dell'S&P500 e la sua varianza al tempo "t+1".
In tutti i modelli GARCH, l'equazione del rendimento è banalmente data da:
y(t+1) = c + epsilon(t+1)
Si noti che c è una costante (mentre, nel caso delle stime rolling, tale termine è sostituito con la media campionaria dei rendimentisulla finestra considerata). Inoltre epsilon(t+1) è una serie di disturbi indipendentemente e identicamente distribuiti con media zero. Naturalmente, la specifica distribuzione dipenderà dal tipo di modello considerato. In alcuni modelli si utilizza il disturbo standardizzato z(t+1) = epsilon(t+1)/sigma(t+1) che, oltre ad avere media nulla, ha evidentemente varianza unitaria.
Modello GARCH(1,1) Normale simmetrico
sigma2(t+1) = omega + alpha*epsilon(t)^2 + beta*sigma2(t)
Classico modello GARCH, quello sviluppato da Bollerslev e Engle per intenderci: tanto più "grande" è la news (cioè epsilon) tanto maggiore è la volatilità. Intuizione semplice, ma di grande efficacia, soprattutto molto aderente alla realtà empirica. La distribuzione di epsilon(t) è Normale con media zero e varianza sigma2(t).
Modello GARCH(1,1) Normale con risposta di volatilità asimmetrica
sigma2(t+1) = omega + alpha*(z(t) - rho*sigma(t))^2 + beta*sigma2(t)
Questo è anche definito il GARCH di Duan (da Jim Duan, che lo ha studiato approfonditamente in una serie di articoli a partire dal 1996). L'asimmetria è introdotta dal parametro rho. Si tratta di un modello molto interessante, perché nel continuo tende al modello a volatilità stocastica di Heston (1993), ampiamente utilizzato nel pricing delle opzioni. La distribuzione di z(t) è normale con media zero e varianza unitaria: ciò implica che epsilon(t) si distribuisce come una Normale con media zero e varianza sigma2(t).
Modello GARCH(1,1) A Mistura Bivariata di Normali
sigma2(t+1,i) = omega(i) + alpha(i)*epsilon(t)^2 + beta(i)*sigma2(t,i) per i = 1,2
Questo modello, sviluppato da Carola Alexander, descrive il processo di varianza come il risultato della ponderazione di due Garch Normali simmetrici. Si tratta di uno dei framework più flessibili, nel senso che è in grado di riprodurre dinamiche time-varying anche del momento terzo e quarto della distribuzione di epsilon(t).
Modello GARCH(1,1) t di Student
Idem come sopra ma con disturbi t di Student. Ricordo che la t di Student è una distribuzione simmetrica ma leptocurtica (con indice di curtosi maggiore di 3 quindi).
Modello GARCH(1,1) t di Student con risposta di volatilità asimmetrica
Idem come sopra ma di nuovo con disturbi t di Student.
E finalmente adesso i grafici del VaR out-of-sample!















{kind=link}